요약
@Transactional 안에서 BCrypt를 실행하면 ~100ms 동안 DB 커넥션을 불필요하게 점유한다.
BCrypt를 트랜잭션 밖으로 꺼내는 것만으로 커넥션 점유 시간을 103ms → 3ms로 줄이고, 로그인 트래픽이 전체 서비스 장애로 전파되는 경로를 차단했다.
들어가며
stylehub 프로젝트에서 회원가입·로그인 API를 개발하면서 비밀번호 암호화에 BCrypt를 사용했다.
처음에는 @Transactional 안에서 BCrypt를 실행했다.
기능은 정상적으로 동작했지만 BCrypt의 동작 방식을 공부하다가 한 가지 수치가 눈에 걸렸다.
BCrypt는 해싱 한 번에 ~100ms가 걸린다.
단순한 속도 문제가 아니었다. 곧바로 다른 의문으로 이어졌다.
"BCrypt가 ~100ms 동안 실행되는 사이, DB 커넥션을 점유하고 있어도 괜찮은가?"
로컬에서는 요청이 한 건씩 들어오니 아무 문제가 없었다.
하지만 StyleHub 프로젝트는 동시에 수백 건의 요청이 몰리는 대용량 트래픽 상황을 전제로 개발하고 있다.
이 의문은 단순한 궁금증이 아니라 서비스 전체를 멈출 수 있는 결함으로 보이기 시작했다.
이 글에서는 그 문제를 발견한 과정, 원인 분석, 그리고 실제 코드로 해결하기까지의 과정을 담았다.
0. 암호화 vs 해싱 — 비밀번호에는 왜 해싱을 쓰는가
BCrypt를 다루기 전에 먼저 암호화와 해싱의 차이를 짚고 넘어갈 필요가 있다.
두 개념을 혼용하는 경우가 많지만, 언제 무엇을 써야 하는지를 명확하게 알고 있어야 한다.
평문 ──[암호화 키]──▶ 암호문
암호문 ──[복호화 키]──▶ 평문 (원본 복원 가능)
암호화(Encryption) — "나중에 원본을 꺼내야 할 때"
암호화는 복호화가 가능한 양방향 변환이다.
키(key)를 가진 사람은 암호화된 데이터를 원본으로 되돌릴 수 있다.
종류 예시 특징
| 대칭키 | AES | 암호화/복호화에 같은 키 사용 |
|---|---|---|
| 비대칭키 | RSA | 공개키로 암호화, 개인키로 복호화 |
해싱(Hashing) — "원본을 알 필요 없고, 일치 여부만 확인할 때
해싱은 복호화가 불가능한 단방향 변환이다.
같은 입력은 항상 같은 출력을 내지만, 출력에서 입력을 역추적할 수 없다.
평문 ──[해시 함수]──▶ 해시값
해시값 ──▶ 평문 복원 불가 (단방향)원본을 몰라도 되는 데이터에 사용한다.
- 비밀번호 저장
- 데이터 무결성 검증 (파일 변조 여부 확인)
비밀번호에 암호화가 아닌 해싱을 써야 하는 이유
구분암호화 저장해싱 저장
| 원본 복원 | 가능 (키 있으면) | 불가능 |
|---|---|---|
| DB 유출 시 | 키까지 유출되면 전체 비밀번호 노출 | 해시값만 유출, 원본 추측 어려움 |
| 서버 내부자 | 키를 가진 사람이 비밀번호 열람 가능 | 원본 확인 불가 |
| 로그인 검증 방식 | 복호화 후 비교 | 재해싱 후 비교 |
비밀번호는 서버가 원본을 알 필요가 없다.
로그인 시 사용자가 입력한 값을 동일한 방식으로 해싱해서 저장된 해시값과 비교하면 된다.
복호화가 가능하다는 사실 자체가 보안상 치명적인 약점이 될 수 있음을 고려하면 단방향성인 해싱은 선택이 아닌 필수다.
단, 해싱 중에서도 MD5, SHA-256 같은 범용 해시 함수는 비밀번호에 적합하지 않다.
연산 속도가 너무 빠르기 때문에 공격자가 초당 수십억 가지 조합을 시도하는 무차별 대입(Brute Force) 공격에 취약하기 때문이다.
이러한 취약점을 보완하기 위해 등장한 것이 바로 '의도적으로 느리게 설계된' 알고리즘이다.
비밀번호에는 의도적으로 느리게 설계된 알고리즘이 필요했고 그게 BCrypt를 선택한 이유다.
1. BCrypt는 왜 느린가
BCrypt는 의도적으로 느리게 설계된 해싱 알고리즘이다.
비밀번호 해킹의 대표적인 방법은 브루트포스(Brute Force) 로 가능한 모든 조합을 대입해보는 것이다.
BCrypt는 해커가 한 번 시도할 때마다 오래 걸리게 만들어 브루트포스를 통한 암호 해독을 사실상 불가능하게 한다.
BCrypt는 cost 값으로 연산 횟수를 조절해 해싱 자체를 느리게 만들어 이 공격을 어렵게 한다.
BCrypt cost란?
cost는 BCrypt가 해싱 연산을 몇 번 반복할지 결정하는 숫자다.
ost가 1 늘어날 때마다 반복 횟수가 2배씩 증가한다.
| cost | 해싱 시간 | 용도 |
|---|---|---|
| 10 | ~80-100ms | 일반적인 서비스 (본 프로젝트 채택) |
| 12 | ~300-400ms | 높은 보안 요구 |
| 14 | ~1,000ms+ | 매우 높은 보안 요구 |
cost=10을 선택한 이유 — "수천 년"과 "수만 년"의 차이는 무의미하다
cost를 올릴수록 보안이 강해지는 건 사실이다.
그런데 트레이드오프를 따져봤다.
cost=10과 cost=12의 차이는 브루트포스 해독 시간이 수천 년에서 수만 년으로 늘어나는 것이다.
공격자 입장에서 수천 년이나 수만 년이나 현실적으로 해독 불가능하다.
반면 서버 입장에서는 cost=12가 cost=10보다 해싱 시간이 약 4배 길다.
로그인 요청이 초당 100건 들어오는 서비스라면 이 4배 차이는 처리량에 직접적인 영향을 준다.
보안 강도가 "충분히 안전한 수준"을 이미 넘어선 상태에서 cost를 올리는 것은 보안 향상 효과는 사실상 없고, 성능 비용만 추가되는 선택이다.
이 판단 하에 본 프로젝트는 일반적인 커머스 서비스 수준의 보안을 전제로 cost=10을 채택했다.
이 느린 연산이 회원가입(해싱)과 로그인(검증) 양쪽에서 모두 실행된다.
2. 문제를 인식한 계기
HikariCP 커넥션 풀의 기본 최대 크기는 10개다.@Transactional 메서드 안에서 BCrypt가 실행되면, 메서드가 끝날 때까지 커넥션이 반환되지 않는다.
간단한 계산을 해보면:
커넥션 1개 점유 시간 = DB 조회 (~3ms) + BCrypt (~100ms) = ~103ms
커넥션 1개 초당 처리량 = 1000 / 103 ≈ 9.7건
HikariCP 풀 10개 기준 = 9.7 × 10 = ~97 req/s초당 97건. 동시 요청이 100건만 넘어도 커넥션 대기가 시작되고 타임아웃이 발생한다.
더 심각한 것은 이 커넥션 풀을 로그인만 쓰는 게 아니라는 점이다.
상품 조회, 주문, 결제 등 모든 API가 같은 풀을 공유한다.
로그인 폭주 → 커넥션 풀 고갈 → 상품 조회 타임아웃 → 주문 API 타임아웃 → 전체 장애하나의 API 병목이 전체 서비스를 마비시키는 장애 전파 패턴이다. 이 구조를 그대로 두면 안 된다고 판단했다.
3. 변경 전 코드 — @Transactional 방식
변경전 코드를 요약하면 다음과 같다
회원가입
@Transactional
public UserSignUpResponse signUp(UserSignUpRequest request) {
// ← 커넥션 획득
userValidator.validateSignUp(request.email(), request.name()); // ~5ms
String encodedPassword = passwordEncoder.encode(request.password()); // ~100ms (커넥션 점유 중)
User user = User.create(request.name(), request.email(), encodedPassword, request.birthDate());
User savedUser = userRepository.save(user); // ~5ms
return UserSignUpResponse.from(savedUser);
// ← 커넥션 반환
}로그인
@Transactional
public UserLoginResponse login(UserLoginRequest request) {
// ← 커넥션 획득
User user = userRepository.findByEmail(request.email()) // ~3ms
.orElseThrow(...);
passwordEncoder.matches(request.password(), user.getPassword()); // ~100ms (커넥션 점유 중)
return UserLoginResponse.from(user);
// ← 커넥션 반환
}두 API 모두 BCrypt 연산이 트랜잭션 안에 포함되어 있다. 커넥션 점유 시간의 97%가 DB와 무관한 CPU 작업이다.
@Transactional 메서드 안에서 BCrypt가 실행되면 커넥션 점유 타임라인이 아래와 같다.
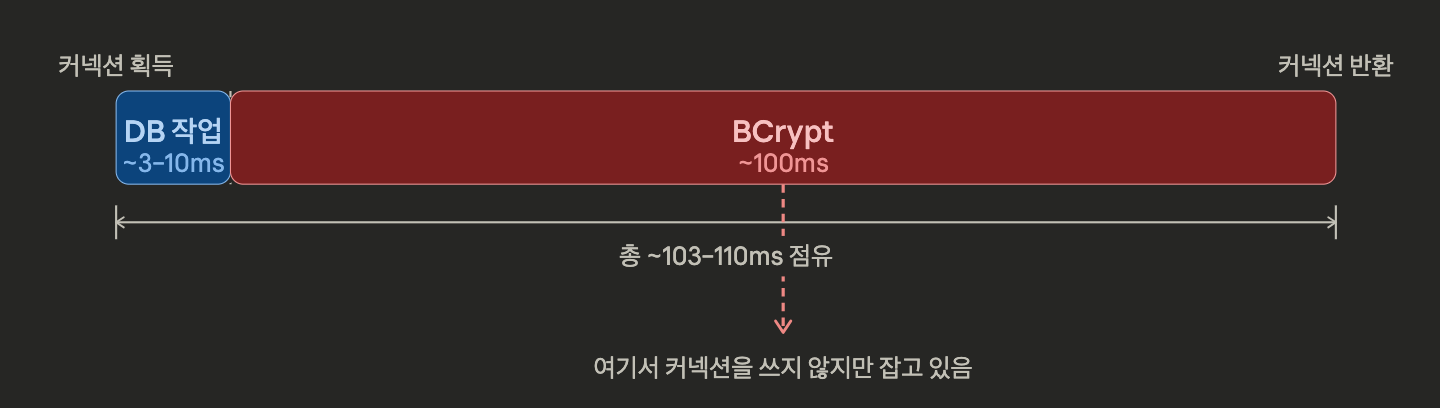
DB 작업은 ~10ms에 불과하지만 BCrypt가 끝날 때까지 커넥션이 반환되지 않기 때문에 총 ~103ms 동안 커넥션을 점유하게 된다.
점유 시간의 97%가 DB와 전혀 무관한 CPU 연산이다.
4. "BCrypt는 CPU 작업인데, 커넥션 점유와 무슨 관계인가?"
사실 BCrypt는 DB랑 아무 관계가 없다. 쿼리를 날리는 것도 아니고, 순수하게 CPU만 쓰는 연산이다. 그러면 왜 커넥션이 문제가 되는 걸까?
문제는 @Transactional이 메서드 진입 시점에 커넥션을 먼저 획득한다는 데 있다.
Spring의 @Transactional은 AOP 프록시로 동작한다.
메서드 진입 시 JpaTransactionManager.doBegin()이 호출되고, Hibernate가 setAutoCommit(false)를 실행하기 위해 커넥션을 즉시 획득한다.
@Transactional 메서드 호출
│
├─ 1. TransactionInterceptor.invoke()
│
├─ 2. JpaTransactionManager.doBegin()
│ └─ EntityManager.getTransaction().begin()
│ └─ Hibernate TransactionImpl.begin()
│ └─ Connection 획득 ← setAutoCommit(false) 호출을 위해
│
├─ 3. 실제 메서드 실행 (findByEmail + BCrypt)
│ └─ BCrypt 실행 중에도 Connection은 반환되지 않음
│
└─ 4. JpaTransactionManager.doCommit()
└─ Connection 반환2번과 4번 사이의 모든 코드가 커넥션을 점유한다.
BCrypt가 DB를 안 쓰더라도 @Transactional의 생명주기 안에 있으면 커넥션 반환이 불가능하다.
호텔에 비유를 하자면
호텔 방(커넥션)을 체크인(트랜잭션 시작)한 상태에서
방 안에서 잠을 자든, 밖에서 산책을 하든(BCrypt)
체크아웃(트랜잭션 종료)하기 전까지 그 방은 다른 손님이 못 쓴다.문제는 "BCrypt가 방을 쓰느냐"가 아니라 "체크아웃 전에 BCrypt가 끼어 있느냐" 다.
트랜잭션이 열려 있는 동안 커넥션은 반환되지 않는데 그 사이에 BCrypt가 실행되기 때문에 커넥션 점유 시간이 불필요하게 길어진다.
원인이 명확해졌으니 해결 방향도 자연스럽게 도출됐다.
@Transactional의 범위에서 BCrypt를 꺼내, DB 작업에만 트랜잭션이 걸리도록 범위를 좁혔다.
5. TransactionTemplate으로 트랜잭션 범위 최소화
TransactionTemplate은 .execute() 블록 단위로 트랜잭션을 열고 닫는다.
블록이 끝나면 즉시 커밋하고 커넥션을 반환한다.
이 특성을 이용해 DB 작업에만 트랜잭션을 걸고, BCrypt는 그 밖에서 실행하도록 구조를 바꿨다.
회원가입은 BCrypt 해싱을 먼저 끝낸 뒤 검증과 저장만 트랜잭션 안에서 처리한다
회원가입
public UserSignUpResponse signUp(UserSignUpRequest request) {
// BCrypt 해싱: 트랜잭션 밖에서 실행 → 커넥션 점유 안 함
String encodedPassword = passwordEncoder.encode(request.password()); // ~100ms
// 검증 + 저장: 트랜잭션 안에서 실행 → 커넥션 점유 최소화
User savedUser = transactionTemplate.execute(status -> {
userValidator.validateSignUp(request.email(), request.name());
User user = User.create(
request.name(), request.email(), encodedPassword, request.birthDate()
);
return userRepository.save(user);
});
return UserSignUpResponse.from(savedUser);
}로그인
public UserLoginResponse login(UserLoginRequest request) {
// 1. 트랜잭션 안: 유저 조회만 (짧은 DB 작업 → 커넥션 빠르게 반환)
User user = Objects.requireNonNull(
transactionTemplate.execute(status ->
userRepository.findByEmail(request.email())
.orElseThrow(() -> new IllegalArgumentException("존재하지 않는 이메일입니다"))
)
);
// 2. 트랜잭션 밖: BCrypt 검증 (커넥션 점유 안 함)
if (!passwordEncoder.matches(request.password(), user.getPassword())) {
throw new IllegalArgumentException("비밀번호가 일치하지 않습니다");
}
return UserLoginResponse.from(user);
}로그인 단계별 상세 흐름 — DB 조회 후 커넥션 반납, 해시 검증
DB에서 암호값을 찾고 커넥션을 반납한 뒤 BCrypt 검증이 이루어지는 과정을 단계별로 풀어봤다.
1. 요청 수신
└─ login(request) 호출
2. transactionTemplate.execute() 블록 진입
└─ HikariCP에서 커넥션 획득
└─ connection.setAutoCommit(false) ← 트랜잭션 시작
3. DB 조회 — 커넥션 사용 (~3ms)
└─ SELECT * FROM users WHERE email = ?
└─ 결과: User 엔티티 반환
└─ user.getPassword() = "$2a$10$xyz..." (BCrypt 해시값이 필드에 담김)
4. transactionTemplate.execute() 블록 종료
└─ connection.commit()
└─ 커넥션을 HikariCP 풀에 즉시 반환 ← 커넥션 해제
└─ 영속성 컨텍스트 종료 (user 객체는 준영속 상태)
※ 이 시점에서 DB 커넥션은 이미 풀로 돌아갔다.
하지만 user.getPassword()에 담긴 해시값은
JVM 힙 메모리에 남아있어 이후 단계에서 사용할 수 있다.
5. BCrypt 검증 — 커넥션 없이 순수 CPU 연산 (~100ms)
└─ passwordEncoder.matches(rawPassword, encodedPassword)
└─ 내부 동작:
a. 해시값($2a$10$xyz...)에서 salt 추출
b. 입력된 rawPassword에 추출한 salt + cost 적용해 재해싱
c. 재해싱 결과와 DB에서 가져온 해시값 비교
d. 일치하면 true, 불일치하면 false 반환
└─ DB 조회 없음, 커넥션 없음, CPU만 사용
6. 응답 반환
└─ 검증 성공 → UserLoginResponse 반환
└─ 검증 실패 → IllegalArgumentException로그인 요청이 들어오면 가장 먼저 transactionTemplate.execute() 블록에 진입한다.
이 순간 HikariCP 풀에서 커넥션을 하나 꺼내고 setAutoCommit(false)로 트랜잭션을 시작한다.
블록 안에서는 딱 하나만 한다. SELECT * FROM users WHERE email = ? 쿼리로 유저를 조회하는 것이다.
이때 DB에서 가져온 User 엔티티 안에 $2a$10$xyz... 형태의 BCrypt 해시값이 password 필드에 담긴다.
조회가 끝나면 블록이 닫히면서 즉시 커밋하고 커넥션을 풀로 반환한다.
영속성 컨텍스트도 이 시점에 닫혀서 user 객체는 준영속 상태가 된다.
여기가 핵심 부분인데. 커넥션은 이미 풀로 돌아갔지만 user.getPassword()에 담긴 해시값은 JVM 힙 메모리에 그대로 살아있다.
DB 연결이 없어도 이 값을 쓸 수 있다.
그래서 이어서 passwordEncoder.matches()를 실행할 때 커넥션 없이 CPU만으로 BCrypt 검증을 완료한다.
내부적으로는 해시값에서 salt를 추출하고, 사용자가 입력한 비밀번호에 그 salt와 cost를 적용해 재해싱한 뒤, 두 해시값이 일치하는지 비교한다.
결국 커넥션이 필요한 구간은 ③번 SELECT 딱 하나, 약 3ms뿐이다.
BCrypt가 ~100ms 동안 실행되는 동안에는 커넥션이 없다.
user.getPassword()에 담긴 해시값은 커넥션이 반환된 이후에도 JVM 힙 메모리에 살아있다.
BCrypt 검증은 DB가 아닌 메모리의 해시값과 CPU 연산만으로 완결되기 때문에
커넥션이 없어도 5(BCrypt 검증)을 실행하는 데 아무 문제가 없다.
변경 전후 커넥션 점유 타임라인을 비교하면 다음과 같다.

변경 전에는 BCrypt가 트랜잭션 안에 묶여 있어 103ms 동안 커넥션을 점유했다.
변경 후에는 DB 작업이 끝나는 즉시 커넥션이 반환되고, BCrypt는 커넥션 없이 독립적으로 실행된다.
커넥션 점유 시간이 103ms에서 3ms로 줄었다.
6. @Transactional(readOnly = true)로 충분하지 않은가?
리팩토링 과정에서 한 가지 반론을 스스로 검토해봤다.
로그인은 읽기만 하는 작업이니 @Transactional(readOnly = true)로도 충분하지 않을까?
readOnly = true는 Hibernate 더티 체킹을 비활성화하고 MySQL InnoDB 읽기 전용 최적화를 적용한다. 분명히 의미 있는 최적화다.
하지만 트랜잭션의 성격을 바꿀 뿐, 범위는 바꾸지 않는다.
.
- Hibernate 더티 체킹 비활성화 → 스냅샷 미생성으로 메모리/CPU 절약
- MySQL InnoDB 읽기 전용 최적화 적용
- 코드가 간결하고 "데이터를 변경하지 않는다" 는 의도가 명확
하지만 readOnly = true는 트랜잭션의 "성격"을 바꿀 뿐, "범위"는 바꾸지 않는다.

readOnly 여부와 무관하게 @Transactional이 붙은 메서드는 진입 시점에 커넥션을 획득하고, 메서드가 끝날 때까지 반환하지 않는다. BCrypt가 DB를 사용하지 않아도 트랜잭션이 열려 있는 동안은 커넥션이 묶여 있다.
| 방식 | 커넥션 점유 시간 | 풀 10개 처리량 | 더티 체킹 |
|---|---|---|---|
@Transactional |
~103ms | ~97 req/s | O (오버헤드) |
@Transactional(readOnly = true) |
~103ms | ~97 req/s | X (절약) |
TransactionTemplate |
~3ms | ~3,330 req/s | X (조회만 수행) |
readOnly는 더티 체킹을 제거하지만, 커넥션 처리량은 동일하다.TransactionTemplate은 커넥션 점유 시간 자체를 34배 줄인다.
8. 처리량 개선 수치
| 항목 | 변경 전 (@Transactional) | 변경 후 (TransactionTemplate) | 개선율 |
|---|---|---|---|
| 커넥션 점유 시간 | ~103ms | ~3ms | 약 34배 감소 |
| 풀 10개 처리량 | ~97 req/s | ~3,330 req/s | 약 34배 증가 |
| 풀 20개 처리량 | ~194 req/s | ~6,660 req/s | 약 34배 증가 |
| 동시 100건 요청 (풀 5개) | 타임아웃 발생 | 전부 성공 | - |
위 수치는 커넥션 풀 관점의 이론적 처리량이다.
9. 그렇다면 이 최적화의 진짜 가치는?
BCrypt는 CPU 바운드 작업이기 때문에 커넥션 풀 병목을 해결해도 CPU가 새로운 병목이 된다.
처리량 자체가 극적으로 늘어나지는 않는다. 그렇다면 이 최적화에 의미가 없는 걸까?
그렇지 않다. 진짜 가치는 처리량 향상이 아니라 장애 격리에 있다.
[변경 전] 로그인 폭주 → 커넥션 풀 고갈 → 상품 조회·주문 등 다른 API도 전부 대기
[변경 후] 로그인 폭주 → 커넥션 3ms씩만 사용 → 다른 API는 정상 동작변경 전에는 커넥션 풀과 CPU 두 가지 모두 병목이었다.
변경 후에는 CPU만 병목이 되며, 커넥션 풀은 여유가 생겨 다른 API에 영향을 주지 않는다.
10. 테스트로 검증하기
이론으로는 충분히 납득이 됐다.
하지만 실제로 커넥션 풀이 고갈되는지 코드로 검증해보고 싶었다.
HikariCP 풀 5개 + 동시 100건 요청으로 변경 전후를 직접 테스트 코드를 작성하여 검증했다.
| 시나리오 | 성공 | 타임아웃 | 결과 |
|---|---|---|---|
| 변경 전 (BCrypt IN 트랜잭션) | 일부 | 다수 발생 | 커넥션 풀 고갈 |
| 변경 후 (BCrypt OUT 트랜잭션) | 100건 전부 | 0건 | 안정적 처리 |
테스트는 BcryptConnectionTest, LoginBcryptConnectionTest에서 확인할 수 있다.
Spring Context 없이 순수 JDBC + HikariCP로 작성해서 커넥션 풀 동작만 격리해서 검증했다.
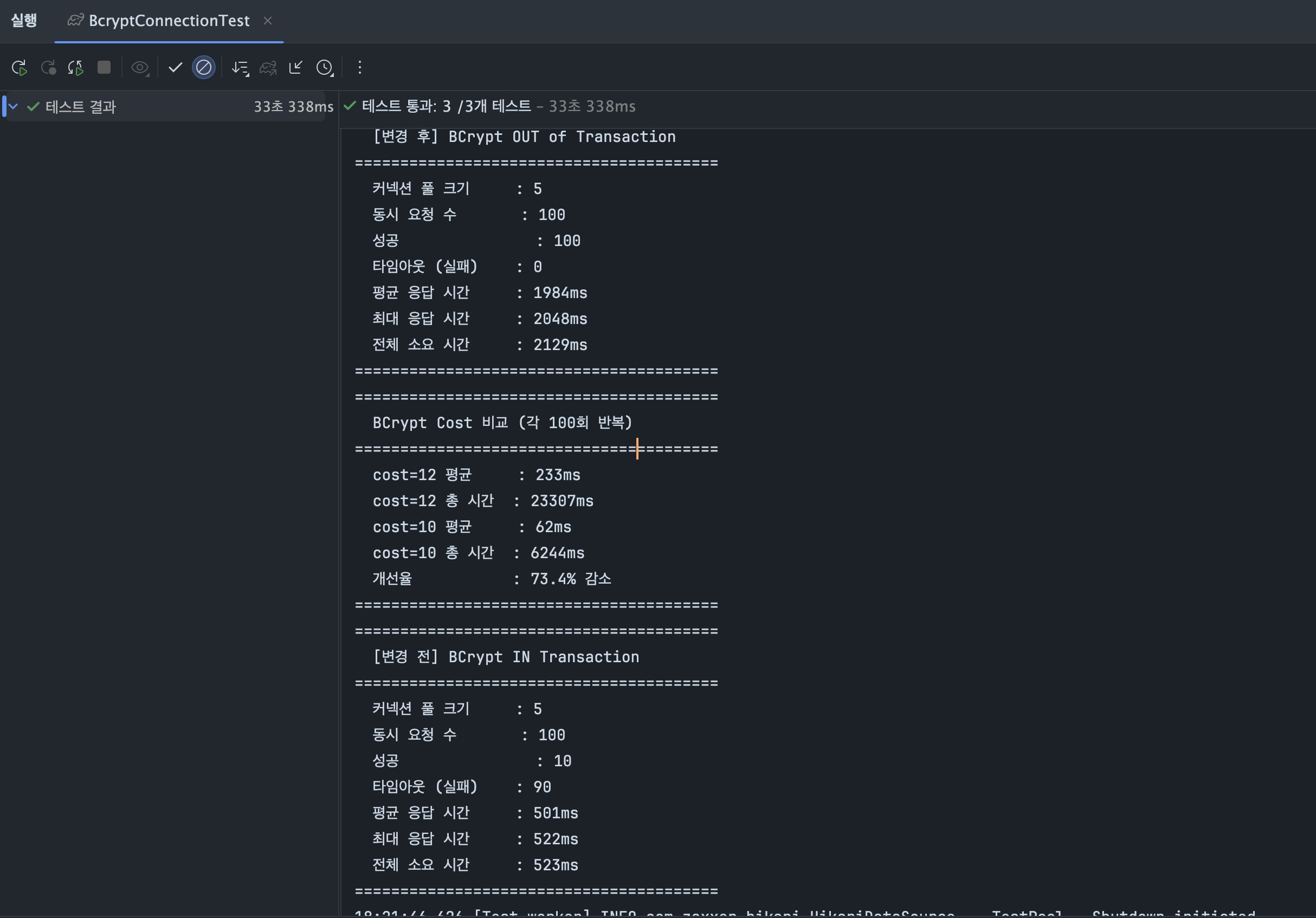
이론적 계산이 실제 코드에서도 동일하게 재현됐다.
변경 전에는 동시 100건 요청 중 90건이 connectionTimeout으로 실패했고 변경 후에는 100건 전부 성공했다.
3개 테스트 모두 통과했고 총 소요 시간은 33초 338ms였다.
지금까지 다룬 변경 사항을 한눈에 정리하면 아래와 같다.

- BCrypt는 트랜잭션 밖에서, DB 작업만 트랜잭션 안에서 실행된다.
- 커넥션은 DB 작업이 끝나는 즉시 반환되고, BCrypt는 커넥션 없이 독립적으로 실행된다.
- 그 결과 커넥션 점유 시간이 로그인 API 는~103ms → ~3ms (약 34배), 회원가입 API ~110ms → ~10ms (약 11배) 감소했다.
마치며
이번 경험을 통해 코드를 작성할 때 단순히 "동작하는가"가 아니라 "공유 자원을 얼마나 오래 점유하는가"를 함께 고민해야 한다는 걸 체감했다.
커넥션 풀처럼 모든 API가 공유하는 자원은 한 곳에서 병목이 생기면 전체가 멈춘다. 로컬 테스트에서는 절대 발견할 수 없는 문제이다.
앞으로 코드를 설계할 때 "이 코드가 대용량 트래픽에서도 괜찮은가", "불필요하게 공유 자원을 점유하고 있지는 않은가"를 먼저 물어보는 습관이 생겼다.
BCrypt를 @Transactional 밖으로 꺼내는 것만으로, 커넥션 점유 시간을 103ms에서 3ms로 줄이고, 로그인 트래픽이 전체 서비스 장애로 전파되는 경로를 차단했다.
'stylehub 프로젝트' 카테고리의 다른 글
| [stylehub#8]100만건 상품 목록에서 Offset 대신 커서 페이징을 선택한 이유 (0) | 2026.03.27 |
|---|---|
| [StyleHub#7]Transactional이 동작하지 않는다? — Spring Self-Invocation 버그 발견과 해결 (0) | 2026.03.17 |
| [StyleHub #5] 왜 QueryDSL을 도입했는가 — JPQL의 한계를 설계 단계에서 미리 마주하다 (0) | 2026.03.09 |
| [StyleHub #3]Spring이라서 JPA를 선택하지 않았습니다 — StyleHub에서 JDBC, MyBatis, JPA를 비교한 이유 (0) | 2026.03.09 |
| [StyleHub #2]커머스 DB 설계: ERD 설계하면서 가장 많이 고민했던 9가지 (0) | 2026.03.08 |